ktsukuda-0415 のすべての投稿
スマートフォンでの歌詞閲覧行動の分析
この研究では、人がなぜ・どのように歌詞を閲覧するのかを分析しています。人がなぜ・どのように音楽を聴くのかを明らかにすることを目的とした研究はこれまでに多数取り組まれてきましたが、人がなぜ・どのように歌詞を閲覧するのかを明らかにした研究はこの研究が世界初です。
最近では、SpotifyやApple Musicなどの音楽配信サービスが提供するスマートフォン用アプリにおいて、ユーザが楽曲を再生中にその楽曲の歌詞を閲覧できる機能が実現されています。この研究では、その機能を使った歌詞閲覧行動に着目し、「なぜ」と「どのように」を調査しています。
「なぜ」を明らかにするために、206名を対象としたアンケート調査を実施しました。歌詞を見る理由として8種類の理由を用意し、各理由で歌詞を見ることがどの程度あるかを5段階(1:まったくない~5:よくある)で回答してもらいました。以下がその8種類の理由と結果です。
- 確認:歌詞を聴き取れなかった箇所が何と歌われているのか確認するため
- 理解:歌詞をより深く理解するため
- 歌唱:カラオケなど人前で歌うためではなく、自分で口ずさむため
- 構造:楽曲の構成(A メロ・B メロ・サビなど)を確認するため
- 練習:カラオケなど人前で歌う練習をするため
- 退屈:手持ち無沙汰を解消するため
- 言語:語学の勉強のため
- 作詞:作詞の勉強のため
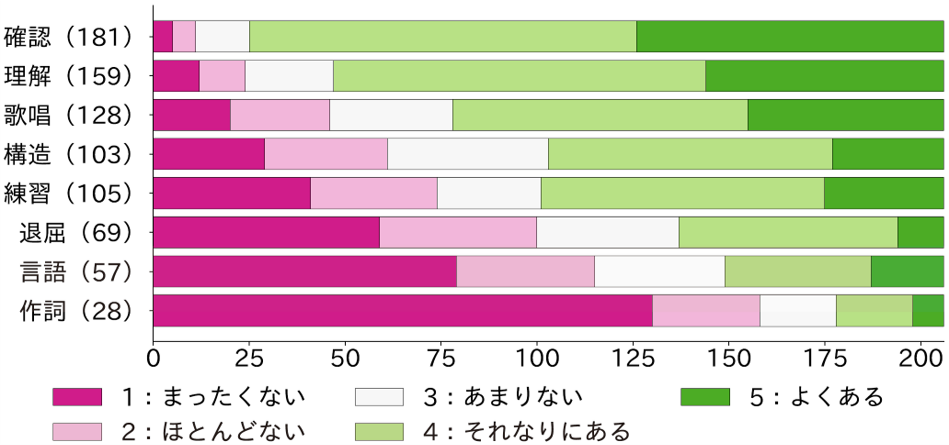
歌詞を見る理由としては「確認」「理解」がポピュラーであり、「歌唱」「構造」「練習」も半数以上の回答者が「それなりにある」または「よくある」と回答していました。論文中では、各理由について「歌詞を見ると決めるのは曲を再生する前か後か」「歌詞の一部分だけ見るか大部分を見るか」といった詳細な分析もしています。また、歌詞を見る理由に応じてユーザを支援するための、歌詞閲覧や楽曲推薦の機能も提案しています。
「どのように」を明らかにするために、スマートフォンの音楽再生アプリから収集された2,300万件以上の歌詞閲覧ログを分析しています。基礎的な統計量の分析として、下の図のように1日の中での各時刻におけるログ数の分布などを調べています(図の「LyLog」は歌詞閲覧ログ、「Lastfm」は楽曲再生ログ)。
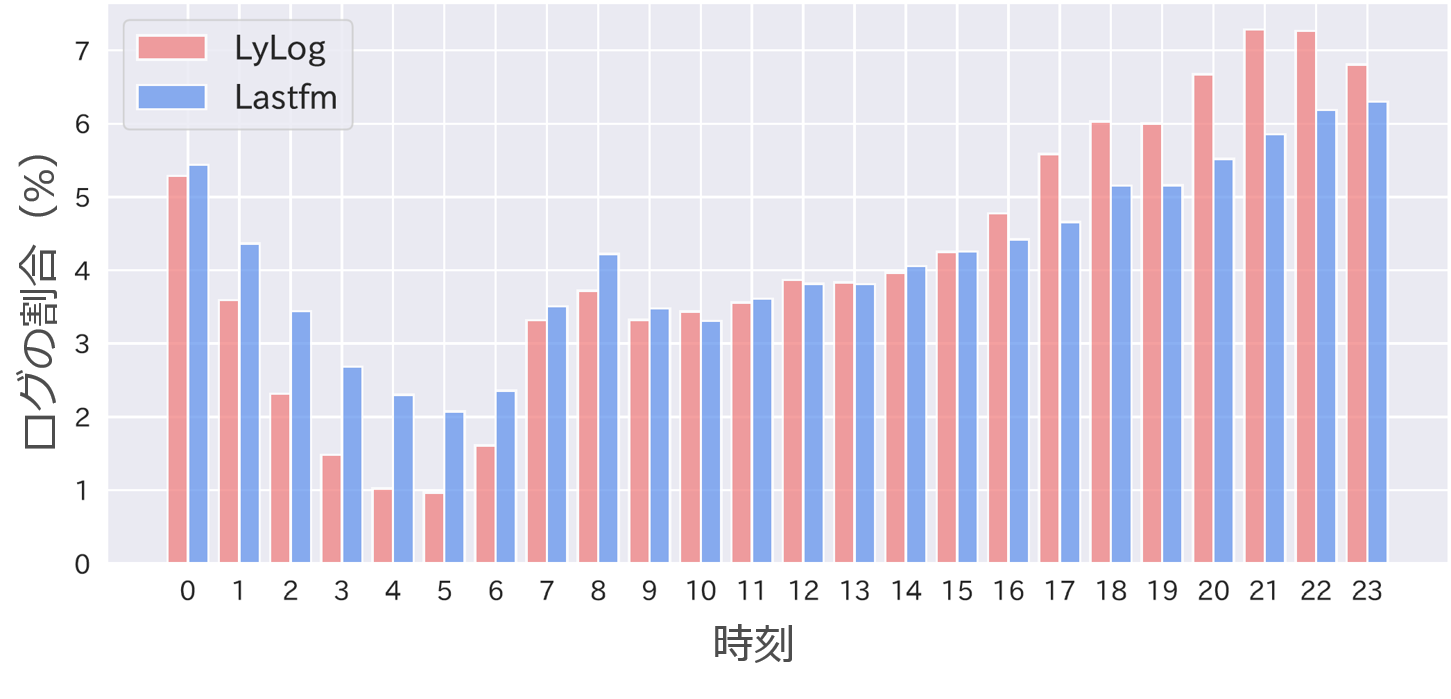
より発展的な分析として、同じ曲の歌詞を繰り返し見る行動も分析しています。ユーザがある曲の歌詞を見始めたとき、最初のうちは短いスパンで繰り返しその曲の歌詞を見るのですが、時間が経つにつれて、その曲に飽きたり、歌詞を覚えて見る必要がなくなったりすることで、徐々にその曲の歌詞を見るスパンが長くなっていくことなどを明らかにしています。
発表論文
- K. Tsukuda, M. Hamasaki and M. Goto
Toward an Understanding of Lyrics-viewing Behavior While Listening to Music on a Smartphone
Proceedings of the 22nd International Society for Music Information Retrieval Conference (ISMIR 2021), pp.705–713, Nov. 2021.
[Paper] [Poster] - 佃洸摂,濱崎雅弘,後藤真孝
人はなぜ・どのように歌詞を閲覧するのか:スマートフォンでの楽曲聴取時の歌詞閲覧行動分析
ARG 第17回Webインテリジェンスとインタラクション研究会(WI2),pp.67-72,2021年12月
[Paper] [Slide]
発表資料
ARG 第17回Webインテリジェンスとインタラクション研究会の発表資料。
画像検索意図の検索満足度と評価指標への影響
概要
この研究では、画像検索時にユーザの持つ様々な意図が、画像検索結果に対する満足度や画像検索結果の評価指標に与える影響を分析しています。分析する際は、先行研究により作成され公開されている、画像検索データセット(タスク実行時のユーザの入力クエリ、クエリの画像検索結果に対する満足度、タスクに関する満足度、クエリと各画像の適合度などが含まれる)を使用しています。ユーザの検索意図として、先行研究に基づいて以下のように階層化された意図を分析対象としています。
- Why型
- 目的別
- Locate:資料作成などに使用するために画像をダウンロードしたい
- Learn:何かについて調べたい
- Entertain:好きな俳優の画像などを検索して楽しみたい
- シチュエーション別
- Work&Study:仕事や勉強のために画像を探したい
- Daily-life:日常生活のために画像を探したい
- How型
- 具体性別
- Specific:あるテーマについて明確に探したいことがある
- General:あるテーマに関する一般的なことを探したい
- 内容別
- Mental Image:探したい画像が明確に頭に描けている
- Navigation:探したい画像が頭に描けていない

画像検索意図が満足度に与える影響
クエリレベルの満足度とタスクレベルの満足度を対象として分析し、以下のようなことが明らかになりました。
- LearnやWork&Studyといった、より切実度の高い意図のもとではクエリ満足度とタスク満足度はともに低くなりやすい。そうした意図を持つユーザは、1個目のクエリで満足のできる検索結果が得られずに苦労しているので、最初のクエリ投入時にクエリ推薦を多めに出すなどの支援が考えられる。
- LearnとGeneralの意図を持ったユーザは、一度満足のできる検索結果が得られた後もクエリを入力し続ける傾向にあり、満足のできるクエリを多く入力するほどタスクの満足度も高くなる。したがって、ユーザが満足する検索結果を返せたとシステムが判断できた場合でも、引き続きユーザの検索支援をすることでさらに満足度を向上できる可能性がある。
画像検索意図が評価指標に与える影響
先行研究で、画像検索に特化した評価指標が提案されています。その評価指標では、画像検索結果では画像がタイル状に並んでおりユーザの視線は列の中央に向けられやすいため、列の中央に近い位置にクエリとの適合度が高い画像が多く配置されているほど評価指標の値が高くなります。画像検索意図がその評価指標に与える影響として以下のようなことが明らかになりました。
- Learn、Daily-life、Mental Imageの意図の元では、提案された評価指標が従来の評価指標よりも優れていた。それ以外の意図では、提案された評価指標と従来の評価指標の間に大きな差は見られなかったため、検索意図に応じた評価指標の提案といった研究トピックが考えられる。
発表論文
- K. Tsukuda and M. Goto
Query/Task Satisfaction and Grid-based Evaluation Metrics Under Different Image Search Intents
Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2020), pp.1877-1880, July 2020.
[Paper] [Slide]
発表資料
SIGIR2020の発表資料です。
繰り返し消費するコンテンツへの推薦理由の提示
概要
この研究では、ユーザが過去に消費したことのあるコンテンツを再度そのユーザに推薦する際に推薦理由を提示する手法を提案しています。既存研究では「あなたが購入した商品と一緒によく購入される商品はこのような商品です」のように、ユーザにとって未知(未消費)のコンテンツを推薦するための推薦理由の生成に焦点があてられてきました。それに対してこの研究では、楽曲の聴取や飲食店の訪問など、ユーザが同じコンテンツ(楽曲や飲食店)を繰り返し消費することの多いドメインを対象として、繰り返し消費されるコンテンツを対象とした推薦理由の生成に焦点を当てている点に新規性があります。
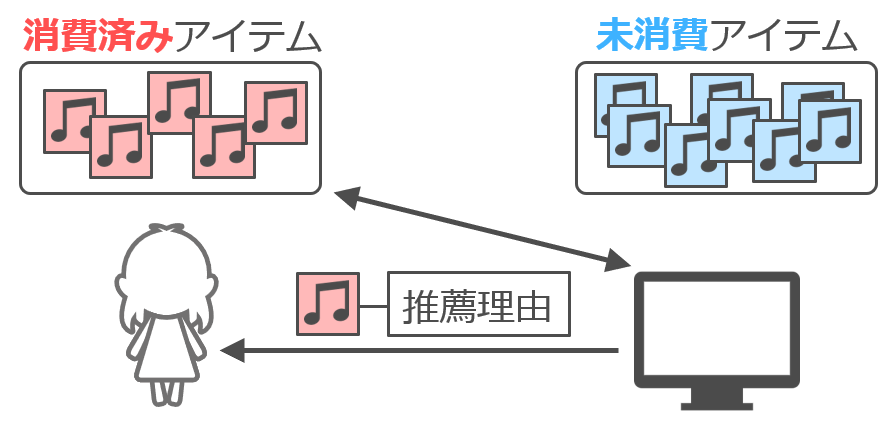
任意のサービスにおいてサービス固有の特徴に応じた推薦理由の生成を可能とするために、人とコンテンツの関わり方を考慮した「属人的要因」「社会的要因」「コンテンツ的要因」の3要因に基づく汎用的な推薦理由の生成フレームワークを提案しています。これにより、例えば楽曲配信サービスであれば、属人的要因を基にすることで「あなたがこの楽曲を初めて聴いてから今日でちょうど5年が経過したので、また聴いてみませんか」といった推薦理由が提示できます。また、訪れた飲食店を記録するサービスであれば、社会的要因を考慮することで「あなたが過去に訪れたこのレストランを好きと言っているユーザが1,000人に到達したので、また訪れてみませんか」といった推薦理由が提示できます。このような推薦理由を提示することで、ユーザは懐かしさや嬉しさを感じながらコンテンツを再度消費することが期待できます。
楽曲の聴取では繰り返し消費されるコンテンツの割合が特に高いことが知られているため、この研究では楽曲推薦における9種類の推薦理由を上記の3要因に基づいて提案し、622名を対象としたアンケート調査を行うことで、提案した推薦理由が消費済みコンテンツの推薦において説得力の向上に有用であることなどを示しました。
発表論文
- K. Tsukuda and M. Goto
Explainable Recommendation for Repeat Consumption
Proceedings of the 14th ACM Conference on Recommender Systems (RecSys 2020), pp.462–467, Sep. 2020.
[Paper] [Slide] - 佃洸摂,後藤真孝
繰り返し消費されるコンテンツを対象とした推薦理由の提示
情報処理学会 情報基礎とアクセス技術研究発表会 研究報告,Vol.2021-IFAT-142,No.3,pp.1-10,2021年3月
[Paper] [Slide]
発表資料
第142回情報基礎とアクセス技術研究発表会の発表資料。
RecSys 2020のポスター。
Kiite Cafe
概要
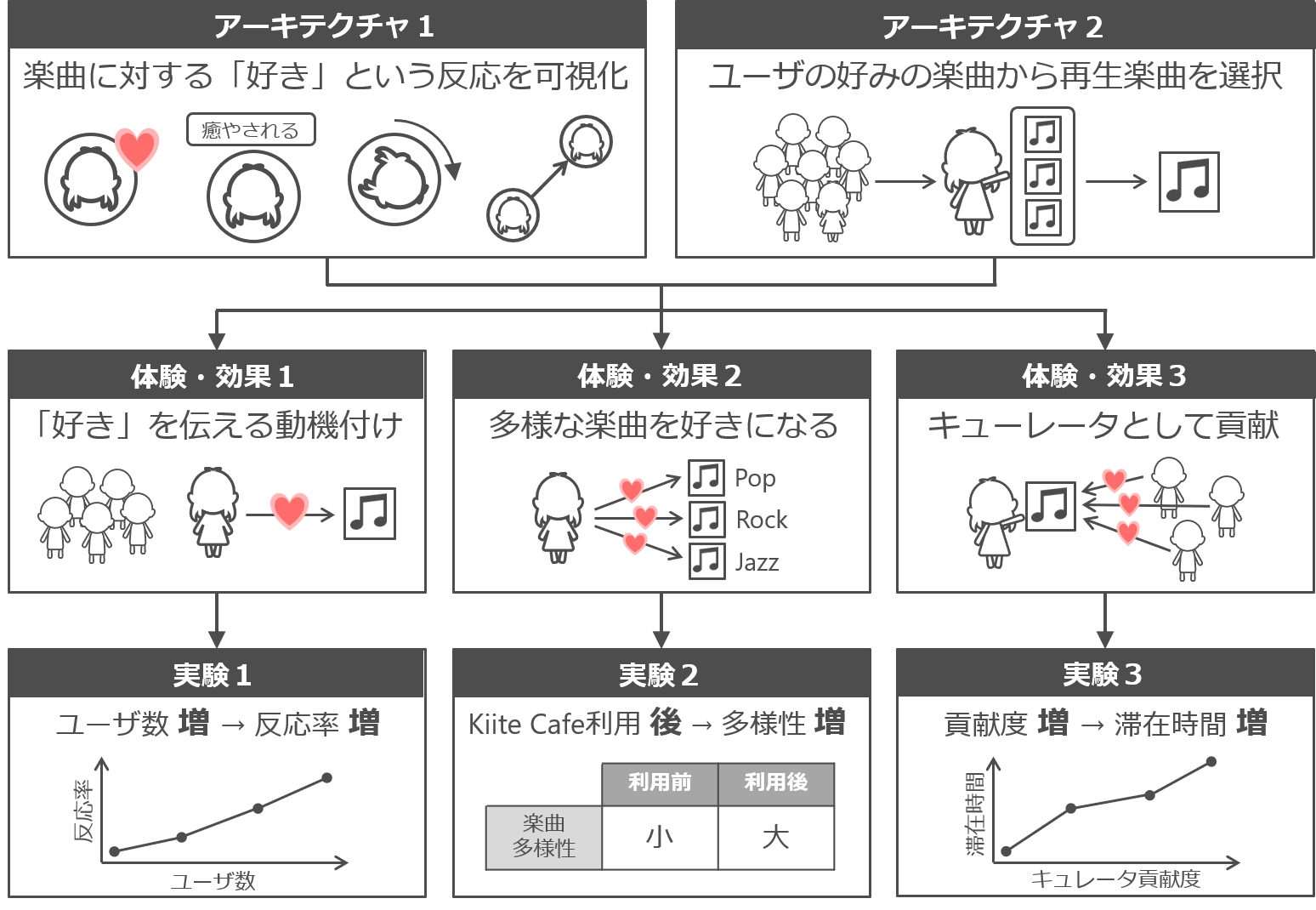
「Kiite Cafe」は、人々がWeb上で集まって同じ瞬間に同じ楽曲を聴きながら、リアルタイムにコミュニケーションが取れる音楽発掘カフェです。Kiite Cafeでユーザが楽曲を聴取する体験は、次の2つのアーキテクチャによって特徴づけられます。
- ユーザの楽曲に対する「好き」という反応が可視化される
- Kiite Cafeで再生される楽曲はユーザの好みの楽曲から選択される
アーキテクチャ1を実現するために、以下の4種類の可視化機能を提供しています。
- 再生中の楽曲を自分のお気に入りに登録すると自分のアイコンにエフェクト付きのハートマークが表示される
- 楽曲に対する印象や気持ちを表現するためにコメントを投稿して自分のアイコンの上に表示させる
- 楽曲を聴いて高まった気持ちなどを表現するために自分のアイコンを回転させる
- 楽曲を聴いて高まった気持ちなどを表現するために自分のアイコンを移動させる
また、アーキテクチャ2を実現するうえでは、Kiite Cafeに滞在している全てのユーザの好みの楽曲(お気に入り楽曲やプレイリストの楽曲)から公平に再生する楽曲が選ばれるような選曲アルゴリズムを実装しています。これにより、KiiteCafeで再生される楽曲の多様性が確保され、自分の好みの楽曲が選択されないことに不満を持つユーザが出ないようになります。
Kiite Cafeのユーザの利用ログを分析することで、2つのアーキテクチャによって以下の3つの効果がもたらされることを明らかにしました。
- アーキテクチャ1によって、Kiite Cafeの滞在ユーザ数が多くなるほど「好き」を伝える意義が大きくなり、ユーザはより積極的に「好き」を伝えるようになる
- アーキテクチャ2によって多様な楽曲を聴く機会が得られるため、ユーザが一人で聴いて好きになる楽曲よりも、KiiteCafeで聴いて好きになる楽曲の方が多様性が高くなる
- アーキテクチャ2によって、どのユーザでもキュレータとして貢献できる機会が得られ、かつアーキテクチャ1によって自分の好きな楽曲を他のユーザが好きになる瞬間を見られるため、キュレータとしての貢献が大きくなるほど自分の好みの楽曲が再度選ばれることが楽しみになり、KiiteCafeの滞在時間が長くなる
Webサービス
謝辞
Kiiteおよびニコニコ動画のユーザ、VOCALOID楽曲のクリエータ、VOCALOID楽曲の日毎・週毎の人気度ランキングの作成者、そしてVOCALOID文化とそれに関連した文化を築き、支援し、楽しんでいる全ての人々に感謝します。また、Kiite を共同開発したクリプトン・フューチャー・メディア株式会社、我々の研究活動を初期は暗黙的に(後に明示的に)応援してきたニコニコ動画に感謝します。
紹介記事
発表論文
- 佃洸摂,石田啓介,濱崎雅弘,後藤真孝
Kiite Cafe: 同じ楽曲を同じ瞬間に聴きながら楽曲に対する気持ちを伝え合う音楽発掘サービス
第26回一般社団法人情報処理学会シンポジウム インタラクション2022, 2022年3月
インタラクティブ発表賞
[Paper] [Slide] - K. Tsukuda, K. Ishida, M. Hamasaki and M. Goto
Kiite Cafe: A Web Service for Getting Together Virtually to Listen to Music
Proceedings of the 22nd International Society for Music Information Retrieval Conference (ISMIR 2021), pp.697–704, Nov. 2021.
第38回 電気通信普及財団賞 (テレコム学際研究賞) 入賞
[Paper] [Poster] - 佃洸摂,石田啓介,濱崎雅弘,後藤真孝
Kiite Cafe: 同じ楽曲を同じ瞬間に楽しんで「好き」が伝わる音楽発掘カフェ
情報処理学会 音楽情報科学研究会 研究報告,Vol.2021-MUS-132,No.15,pp.1-10,2021年9月
[Paper] [Slide]
発表資料
第26回一般社団法人情報処理学会シンポジウム インタラクション2022の登壇発表資料です。
推薦理由の多様化
概要
この研究では、ユーザにアイテムを推薦する際に、アイテムの多様化に加えて、推薦理由も多様化するための手法を提案しています。下図のようにアーティストの推薦システムを例にとると、推薦理由というのは「The Beatlesはあなたの好きなアーティストOasisに似ているのでお薦めです」のような「アーティストベース」のものや、「The Beatlesはあなたの友人のTomが好きなアーティストなのでお薦めです」のような「友人ベース」のものがあり、全部で7種類の推薦理由を扱っています。
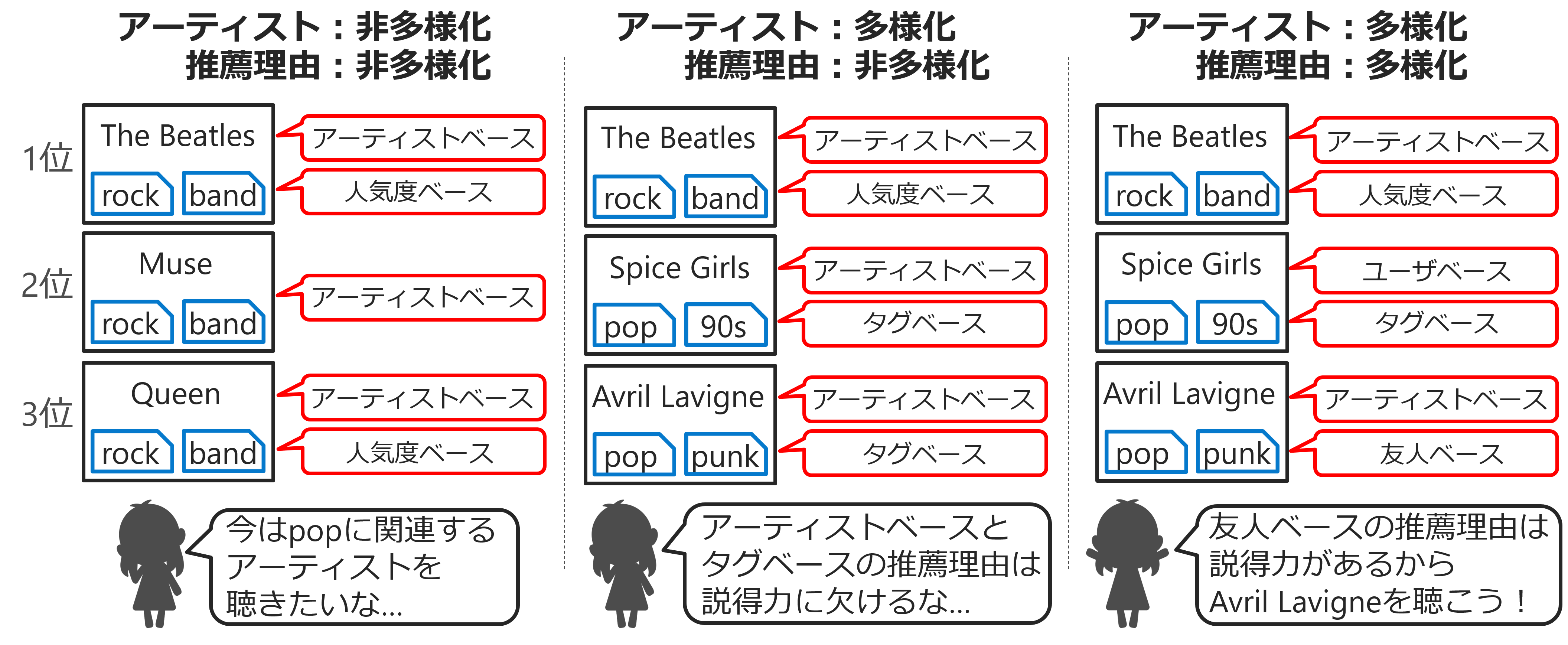
ロックが大好きでポップも少し好きというユーザに対して、一番左の推薦リストのように、ロックのアーティストばかりを上位に推薦すると、ユーザが「今はポップ系のアーティストの曲を聴きたい」という意図を持っているときに対応できません。そこで、アーティストのタグを使うことで、真ん中の推薦リストのように、ロックだけでなくポップに関連するアーティストも推薦されるようにします。
しかし、2位と3位のポップ系のアーティストには、いずれもアーティストベースとタグベースの推薦理由が提示されているため、ユーザがこれらの推薦理由は説得力に欠けると感じると、いずれのアーティストも聴かれない可能性があります。そこで、右の推薦リストのように、アーティストの多様化に加えて推薦理由も多様化することで、ポップ系のアーティストに別々の推薦理由が提示されるようにします。こうすることで、友人ベースの推薦理由に説得力があると思っているユーザであっても、聴きたくなるアーティストを1組は見つけられる可能性を高くしています。
推薦時にアイテムの多様化を行う研究はこれまでにも取り組まれていましたが、推薦理由の多様化に初めて着目し、そのための手法を提案した点がこの研究の貢献のひとつです。推薦理由の多様化手法では、推薦リスト内での任意のアイテム間の推薦理由の多様化に加えて、類似したアイテム間では類似した推薦理由が提示されないように推薦理由を多様化するという工夫をしています。より詳細な内容は下にある論文PDFをご覧ください。
発表論文
発表資料
RecSys2019論文読み会の発表資料です。
RecSys 2019のポスター発表用資料です。
クリエータのコラボレーション分析
概要
この研究では、複数人のクリエータが協力してひとつの動画コンテンツを創作する「コラボレーション」に関する分析をしています。ニコニコ動画に投稿された動画の中でも、VOCALOIDを用いて創作された楽曲を歌ったり、踊ったり、演奏したりする「派生動画」におけるコラボレーションを扱っています。

分析はコラボレーションと(1)動画の視聴のされ方との関係、(2)クリエータの活動との関係、(3)クリエータの特性との関係、といった観点から行いました。代表的な結果を以下に記述します。
動画の視聴のされ方との関係
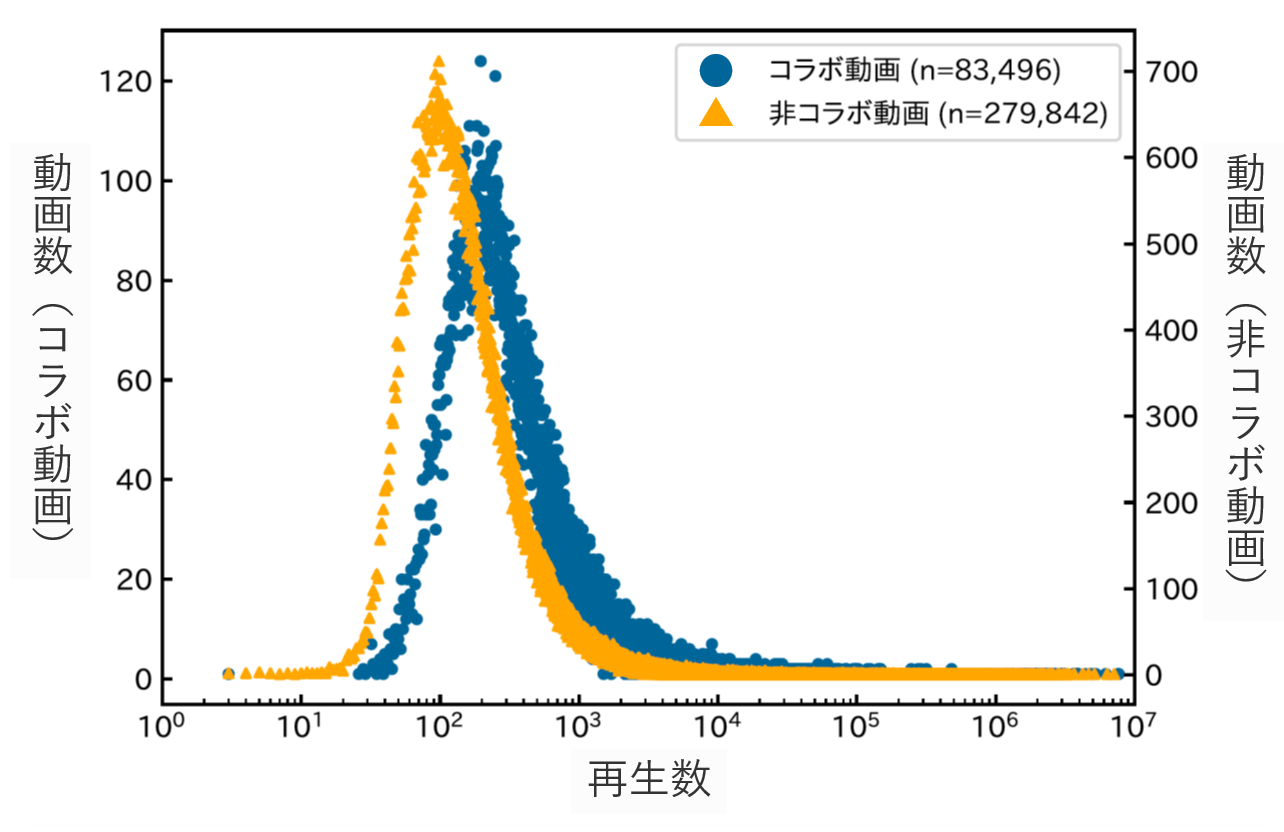
コラボレーションによって創作された動画(コラボ動画)と、一人のクリエータによって創作された動画(非コラボ動画)の再生数の分布を調べると下図のようになりました。コラボ動画の方が分布が右に偏っていることから、コラボ動画の方が再生数が多い傾向にあることがわかりました。コラボ動画の場合、創作に関わった各クリエータの動画を日頃視聴して
いるユーザが同じコラボ動画を視聴するために再生数が多くなるのではないかと推測されます。
クリエータの活動との関係
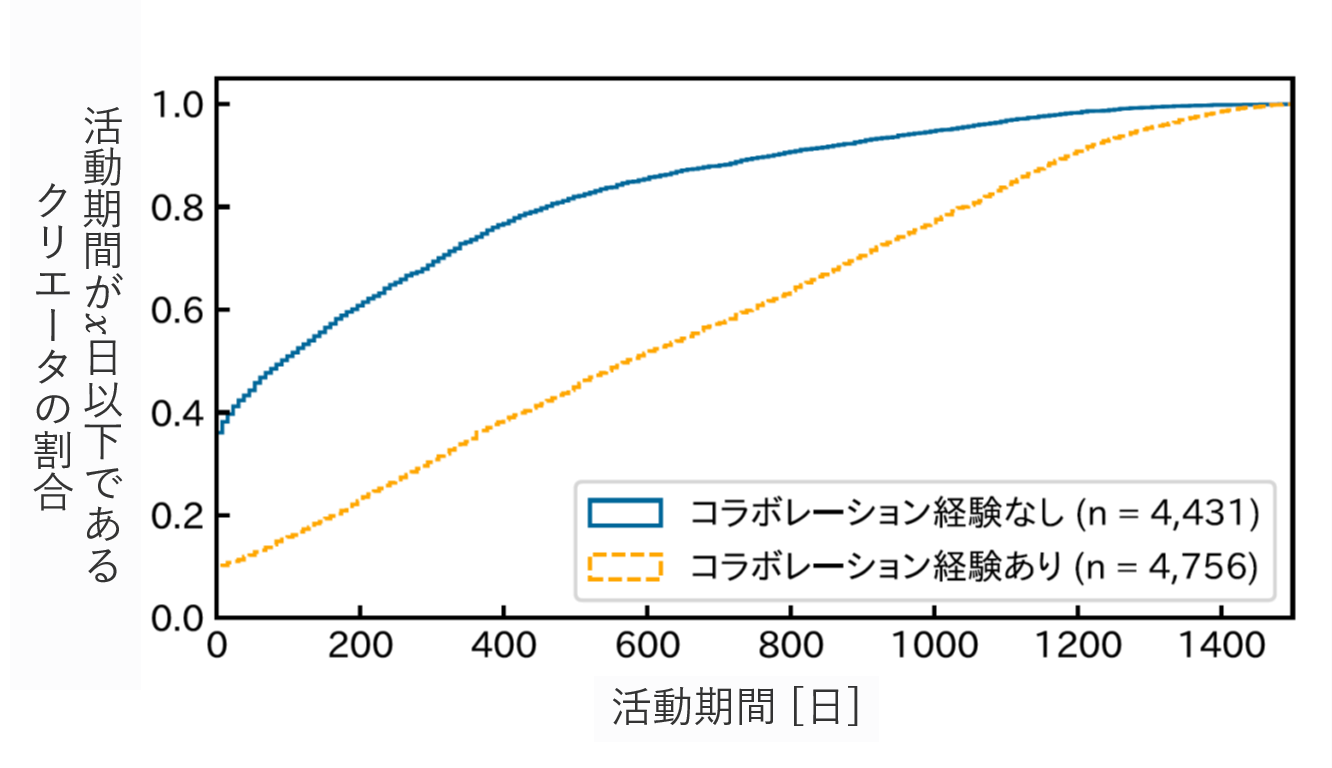
コラボレーション動画を一度でも創作した経験のあるクリエータと、一度も経験したことのないクリエータの活動期間の長さの分布を調べると下図のようになりました。クリエータの活動期間は、その人の最初の動画投稿日と最新の動画投稿日の差により定義しています。図から、コレボレーションの経験したクリエータの方が活動期間が長い傾向にあることがわかりました。現状では相関があることだけがわかっており、因果関係までは検証できていませんが、コラボレーションを経験した結果として活動期間が長くなることが明らかになれば、より容易にコラボレーションができるような環境づくりをしてクリエータ間のコラボレーションを支援する研究への発展などが期待できます。
より詳細な内容は下にある論文PDFをご覧ください。
発表論文
- S. Hironaka, K. Tsukuda, M. Hamasaki, and M. Goto
Collaboration in N-th Order Derivative Creation
Proceedings of the 12th International AAAI Conference on Web and Social Media (ICWSM 2018), pp.608-611, Jun, 2018.
[Paper] - 廣中詩織,佃洸摂,濱崎雅弘,後藤真孝
N次創作動画におけるクリエータのコラボレーションに関する分析
ARG 第11回Webインテリジェンスとインタラクション研究会(WI2),2017年12月
萌芽研究賞
ステージ発表選出
[Paper]
依頼講演
- 廣中詩織,佃洸摂,濱崎雅弘,後藤真孝
N次創作動画におけるクリエータのコラボレーションに関する分析
第6回WI2研究会ステージ発表,2018年12月
ユーザ生成コンテンツ推薦
概要
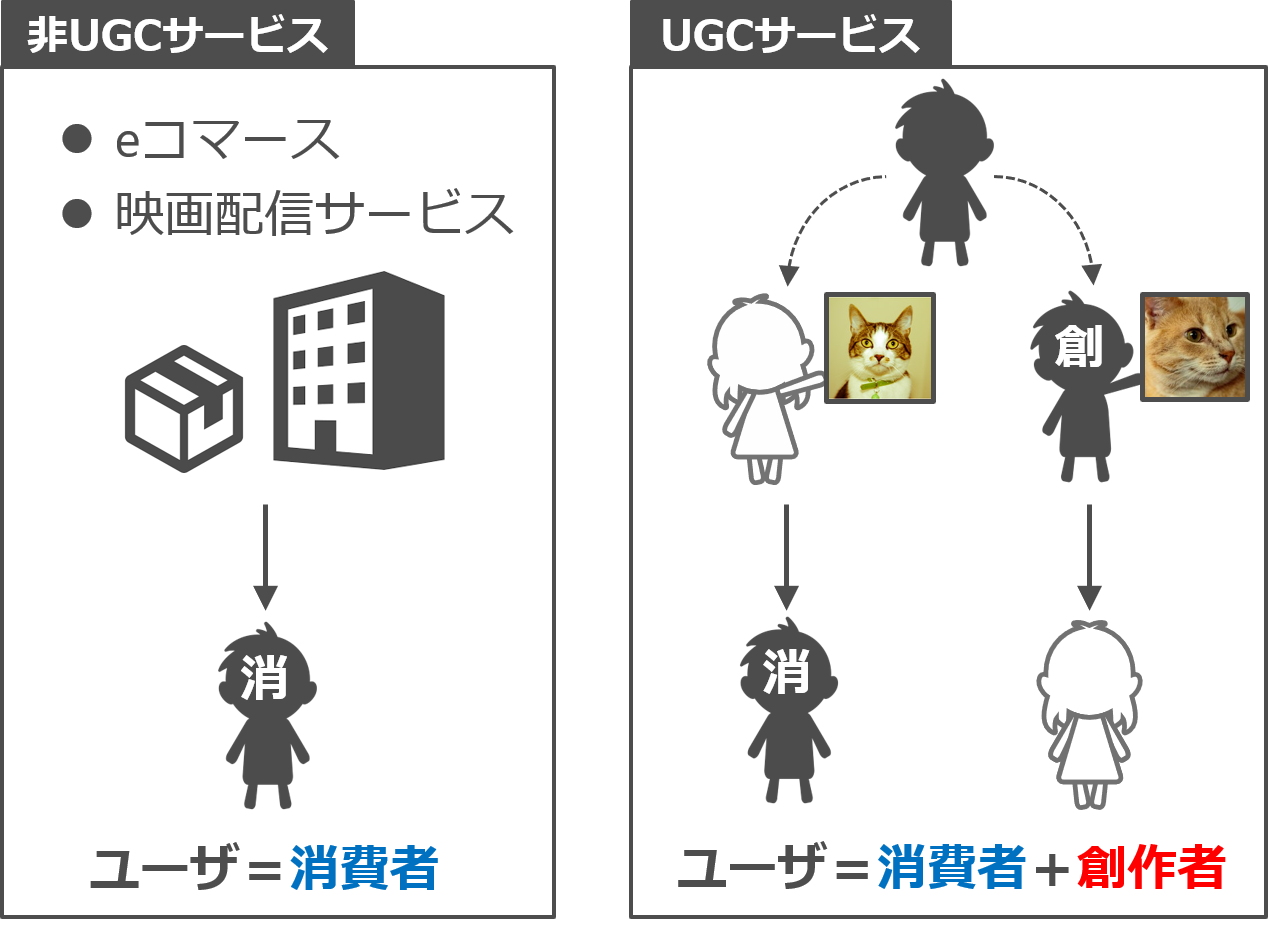
この研究では、ユーザ生成コンテンツ(UGC)を推薦するためのモデルを提案しています。UGCとは、プロのクリエータではない一般の人々によって創作されたコンテンツのことで、YouTubeの動画やFlickrの写真などがその一例としてあげられます。
UGCを扱わない一般的なeコマースサービスなどでは、ユーザは消費者としての役割しか持たないのですが、UGCを扱うWebサービスでは、一人のユーザが消費者としての役割に加えて創作者としての役割も持つのが特徴です。この特徴を活かし、従来の推薦モデルが「ユーザがどのコンテンツを消費したか」という情報だけを使っていたのに対して、提案モデルではその情報に加えて「ユーザがどのコンテンツを創作したか」という情報も使い、それにより推薦精度の改善を実現しました。
より具体的には、まず各ユーザに対して消費者に対応するk次元ベクトルと創作者に対応するk次元ベクトルを用意します。そのうえで、ユーザuの消費者としての性質と創作者としての性質が似ていれば、uの消費者ベクトルの値と創作者ベクトルの値が近くなるように目的関数に制約を加えます。
このとき、「uの消費者としての性質と創作者としての性質の類似度」≒「uの消費コンテンツと創作コンテンツの類似度」≒「uの消費コンテンツの消費ユーザとuの創作コンテンツの消費ユーザの類似度」とみなして類似度を測ります。「uの消費コンテンツの消費ユーザ」は下図のユーザ集合Aに、「uの創作コンテンツの消費ユーザ」は下図のユーザ集合Bに相当し、AとBの重複が大きくなるほどuの消費者ベクトルの値と創作者ベクトルの値が近くなるようにベクトルの値を学習します。
実験を通して、提案モデルの推薦精度がRecSys 2018で提案されたUGC推薦の最新手法の精度を上回ることを示しました。
より詳細な内容は下にある論文PDFおよび発表スライドをご覧ください。

発表論文
- K. Tsukuda, S. Fukayama, and M. Goto
ABCPRec: Adaptively Bridging Consumer and Producer Roles for User-Generated Content Recommendation
Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2019), pp.1197-1200, July 2019.
[Paper] [Poster] - 佃洸摂,深山覚,後藤真孝
ABCPRec:ユーザの消費者としての役割と創作者としての役割の適応的対応付けによるユーザ生成コンテンツ推薦
ARG 第14回Webインテリジェンスとインタラクション研究会(WI2),2019年6月
優秀研究賞
優秀ポスター発表賞
[Paper] [Slide] [Poster]
招待講演
- 佃洸摂
ABCPRec:何を創作したかという情報がコンテンツの消費時に反映されるユーザ生成コンテンツ推薦手法
第12回Webとデータベースに関するフォーラム(WebDB Forum 2019)先端研究解説セッション2,2019年9月
[Slide] [Poster]
発表資料
WebDB Forum 2019の登壇発表の資料です。
WebDB Forum 2019のポスター発表の資料です。
DEIM2017で発表した主著論文が最優秀論文賞を受賞しました
データベースコミュニティにおける最大の国内会議DEIM2017で発表した主著論文「Songrium派生要因分析:N次創作活動のモデル化による派生要因鑑賞サービス」が最優秀論文賞を受賞し、2017年6月24日に行われた授賞式に出席してきました。
DEIMの口頭発表には、次の2種類のセッションがあります。(1)博士後期課程の学生、博士号取得希望の学生および社会人、博士号取得後3年以内の若手研究者が対象のPh.Dセッション。(2)それ以外の学生・研究者が対象の一般セッション。最優秀論文賞はPh.Dセッション、一般セッションそれぞれから1本ずつ選ばれます。私は博士号取得後2年半であったため、Ph.Dセッションで発表しました。今回発表した内容の概要はこちらからご覧いただけます。
特にPh.Dセッションでは、トップレベルの国際会議に採択された研究を始めとして、質の高い研究が多いように思います。Ph.Dセッションの他の方の発表を色々と聞きましたが、研究テーマとして面白いことに加えて、技術的にも深いことをしている研究が多く、素直に「みんなすごい研究をしてるな」と思いました。そんな中で、最優秀論文賞の受賞の通知を貰ったときは、喜ぶよりも先に非常に驚きました。我々の論文を評価していただいた委員の皆さまに改めて感謝申し上げます。
今後も、国際会議で発表することはもちろんですが、国内会議でも積極的に発表し続けたいと思います。


SoC2017 参加報告
2017年6月23日と24日にリクルートテクノロジーズで開催されたSoC2017に参加しました。SoCは「ソーシャルコンピューティング」を指しており、ソーシャルコンピューティングとは、SNSを始めとした、コンピュータを通してコンテンツや人をつなぐ仕組みのことです。SoCでは通常の研究会に比べて、特に企業の方の招待講演が充実しているという特徴があります。今年は、2日間で5件の招待講演があり、1件あたりの発表時間は1時間という充実ぶりでした(プログラム)。以下では、5件の招待講演のうち2件について、簡単な感想とともに紹介します。
仕掛学:データなき世界へのアプローチ
講演者:松村 真宏 先生(阪大)
街中のゴミ箱にバスケットボールのネットを取り付けることで、人がゲーム感覚でゴミを捨てたくなり、ポイ捨てを減らす、というのが「仕掛け」の代表的な例です。講演では冒頭から、世界各地で実際に実施された20個以上もの仕掛けの例をあげていました。沢山の事例を見る中で、思わず行動したくなる仕組みが備わっていれば仕掛けと呼べるのかな、ぐらいに考えていたのですが、例を列挙した後で、仕掛けが満たすべき3つの要件に関する話がありました。以下がその3要件です。
- 公平性:誰も不利益を被らない
- 誘引性:思わずその行動を取りたくなる
- 目的の二重性:仕掛ける側と仕掛けられる側で目的がことなる
ともすると、なんでもかんでも仕掛けなんです、となってしまいかねないのですが、このように要件が明確になっていることで、研究の対象として扱いやすくなっていると感じました。
データを分析することで問題に対処することが盛んに行われていますが、新しい事象に関してはデータが存在しなかったり、人の内面に関してはデータが十分に取れなかったりします。また、ゴミのポイ捨てを減らすためのアイデアは、いくらデータを見ても思いつくものではありません。そういうときこそ仕掛け学が活きる、という話で講演を締めくくられていました。
リクルートグループの現場事例から見るAI/ディープラーニング技術のビジネス活用と、”A3RT” 外部公開の裏側
講演者:奥田 裕樹 さん(リクルートテクノロジーズ)
リクルートテクノロジーズが公開している、機械学習に関するAPI提供サービス「A3RT」に関する講演でした。前半では、どういったAPIが提供されているか、各APIをどのように使うか、を実際に動かしながら説明していました。
後半は、A3RTを作る際の思想に関する話でした。APIを提供する狙いや、サービスとして継続的に提供し続ける上でのポイントといった様々な話の中でも、機械学習によって何をしなければならないかを適切に見極めることの重要性に関する話が印象に残りました。機械学習が流行っているからといって、闇雲に機械学習を使ってAPIを提供するのではなく、機械学習を使うことが有用な問題、解決することがユーザにとって本当に有用な問題を吟味して、APIを提供していることがよくわかりました。講演では、アメリカの心理学者アブラハム・マズローの「ハンマーを持つ人には、すべてが釘に見える。」という言葉と共にこの点の思想が語られていました。
講演のあと、奥田さんと話をする機会があったのですが、このブログの論文紹介記事を見てくださっている、ということを聞いて驚きました。
まとめ
SoCには初めて参加しましたが、研究発表・招待講演ともに、質疑の時間がかなり長くとられている点が非常に良かったです。参加者は100名ほどで規模が大きすぎないこともあり、質問をしやすい雰囲気で、私も何度か質問しました。研究会で複数の企業の方の講演をこれだけじっくり聞けることはあまりないので、来年もタイミングが合えばぜひ参加してみたいです。