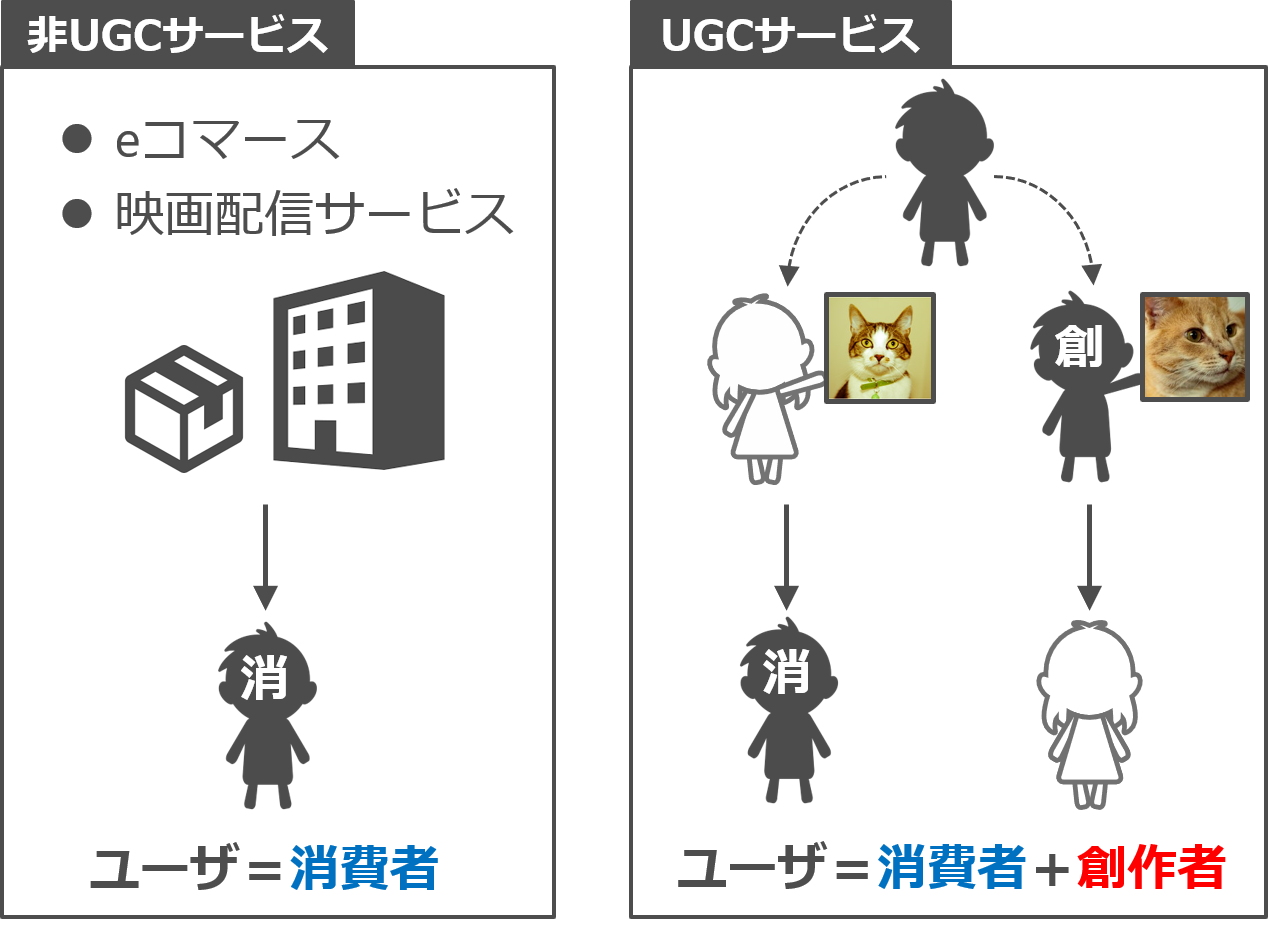
概要
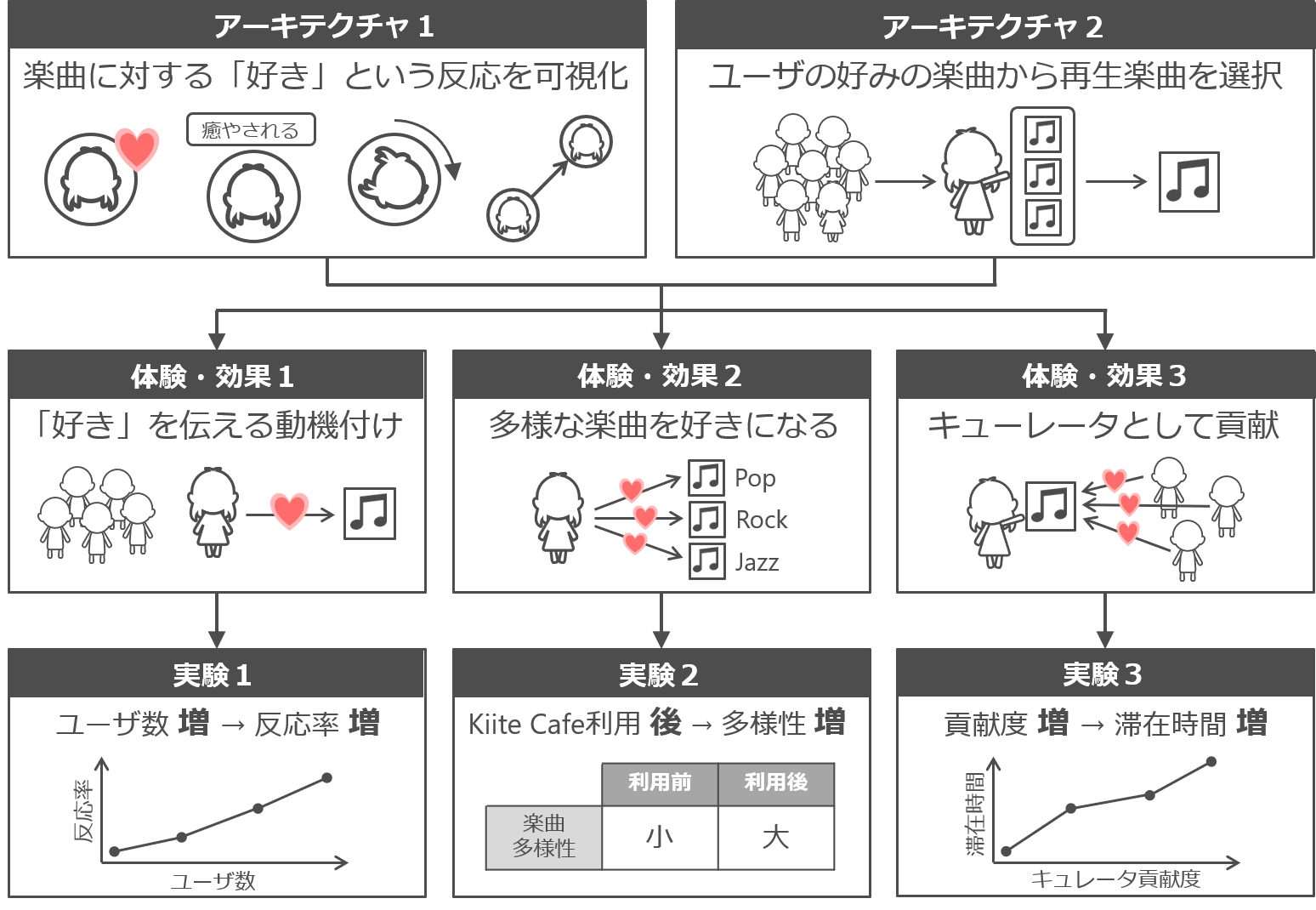
「Kiite World(キイテワールド)」は、マップ上でソーシャルな楽曲探索が可能なWebサービスです。これまでにも、マップ上に楽曲を配置して、ユーザが楽曲を探索可能にするシステムは多数提案されてきましたが、従来のシステムはユーザが一人で探索することを前提としていて、ソーシャルな視点が欠けている点が重要な課題のひとつとして指摘されていました。それに対してKiite Worldでは、50万曲以上の楽曲が配置されたマップ上で、ユーザがアバターを移動させながら、次の3つのソーシャルなインタラクションを行えます。
- マップ上でのプレイリストの共有:自分が作成したプレイリストのうちの一つを指定し、自分の好きな音楽を表現する「マイKiite World」としてマップ上に公開でき、ユーザは互いの「マイKiite World」を訪問しあえる。
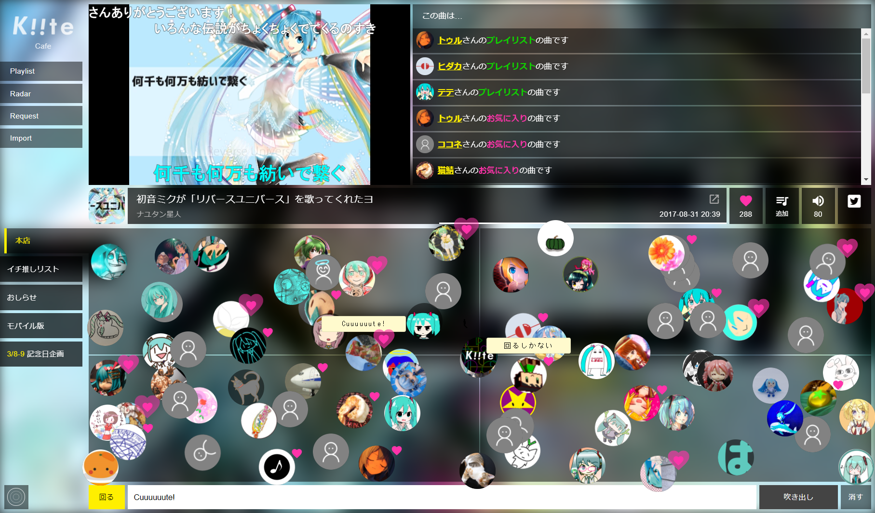
- 楽曲の同期再生:Kiite Worldのマップ上で他のユーザが楽曲を探索したり楽曲を聴いたりする様子がリアルタイムに可視化され、さらに、自分が興味を持ったユーザが楽曲を聴いていたら、その楽曲再生に同期して一緒に音楽を聴きながら好みの楽曲を探せる(左下図)。
- イベントの開催:音楽イベントで大勢の人々が一体感を感じながら一緒に音楽を聴いて楽しむように、「マイKiite World」のマップ上で自分の楽曲再生に大勢のユーザから同期してもらうことで、同じ瞬間に同じ楽曲を聴くことを楽しめるイベンを、Kiite World のユーザの誰もが手軽に開催できる(右下図).
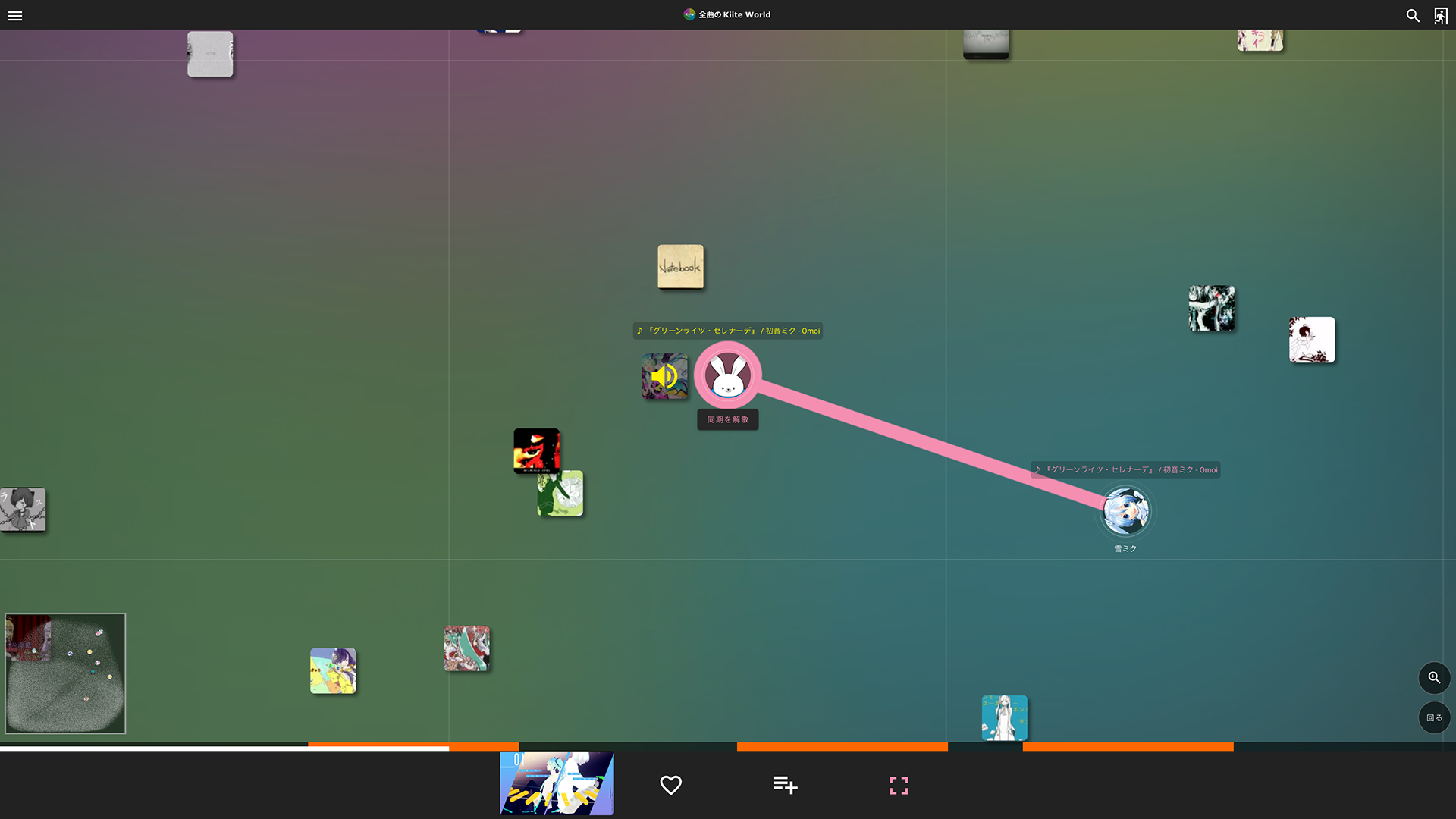
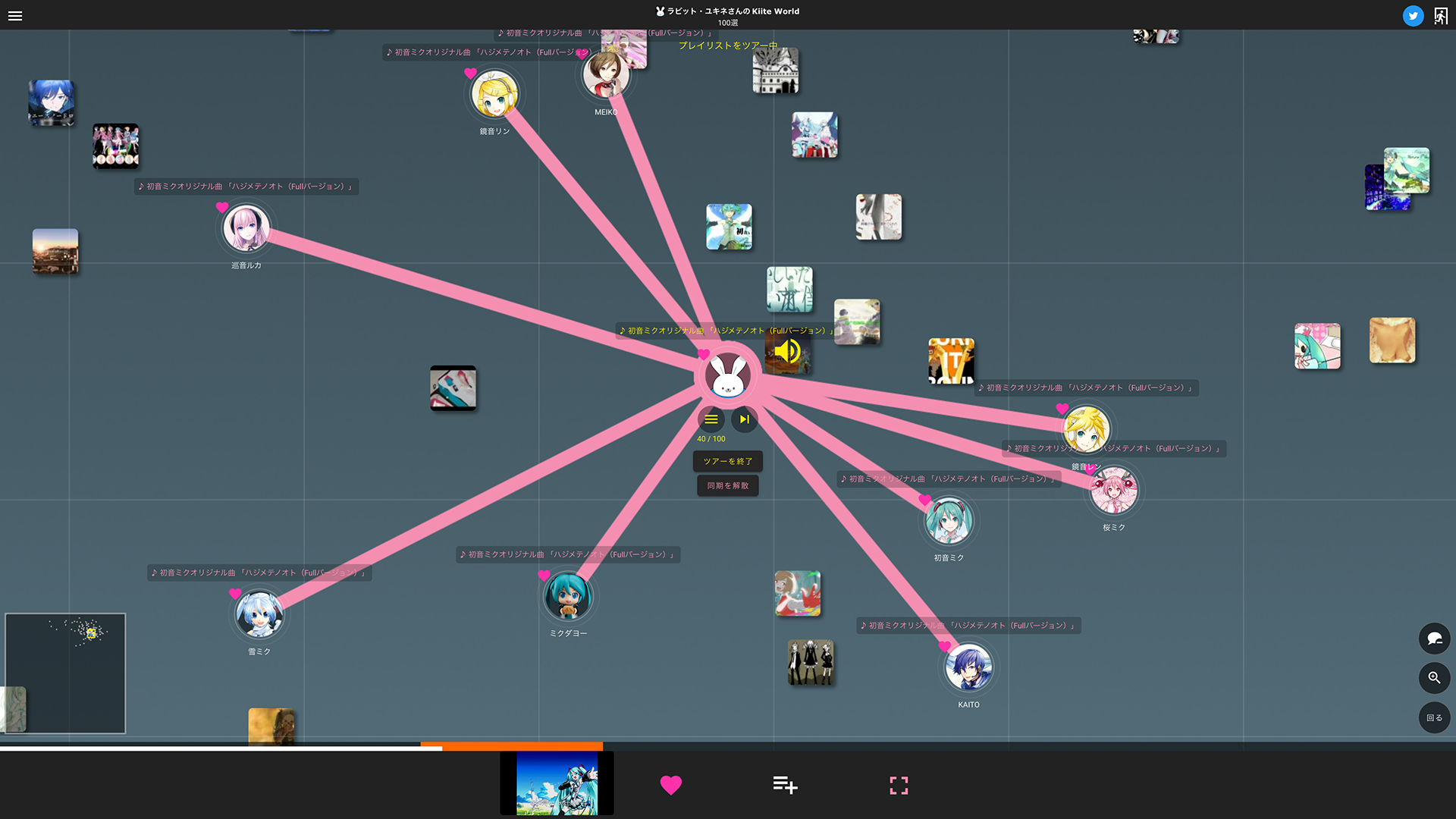
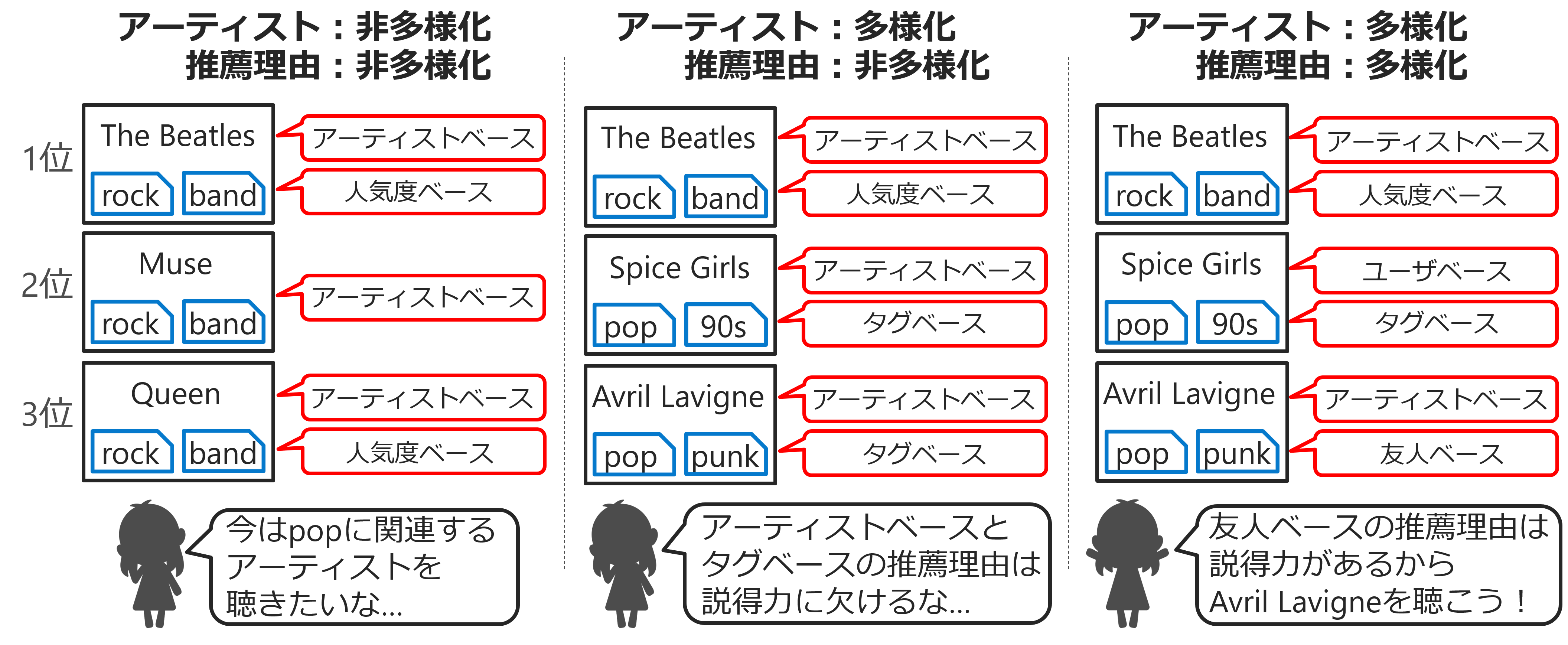
楽曲の配置は、音楽発掘サービス「Kiite(キイテ)」の推薦モデルを元に決められています。推薦モデルでは楽曲が高次元ベクトルで表されており、UMAPを用いて2次元ベクトルに変換することで座標値を計算しています。このとき、単純にUMAPを適用するだけでは適切な変換ができないので、距離関数を変えたり実行時のランダム性をなくしたりといった工夫を加えています。さらに、推薦モデルに含まれるユーザのベクトルも2次元に変換してマップ上に各ユーザの「家」として表示しています。ユーザの家の近くには、そのユーザが好きそうな曲が配置さているため、自分の家を起点として効率的に好みの楽曲を探索できます。
Kiite Worldのユーザの利用ログを分析した結果、ユーザは一人でマップ上を探索するときよりも、他のユーザに同期しながらマップ上を探索した方が、本来の好みとは遠い曲を好きになる機会を得られるなど、マップ上の楽曲探索にソーシャルなインタラクションを導入することの様々な効果が明らかになりました。

Webサービス
プレスリリース
- 産総研:音楽推薦に基づくマップ上で好みの楽曲を共有できる音楽発掘サービス「Kiite World」を公開 -好みの100曲をお互いに公開してマップ上で一緒に聴きながら好みの楽曲を見つけ出せる-(2023/07/19)
- クリプトン・フューチャー・メディア:音楽印象分析・音楽推薦を駆使して楽曲と出会える音楽発掘サービス「Kiite」を公開(2023/07/19)
- 科学技術振興機構(JST):音楽推薦に基づくマップ上で好みの楽曲を共有できる音楽発掘サービス「Kiite World」を公開 ~好みの100曲をお互いに公開してマップ上で一緒に聴きながら好みの楽曲を見つけ出せる~(2023/07/19)
発表論文
- Kosetsu Tsukuda, Takumi Takahashi, Keisuke Ishida, Masahiro Hamasaki, and Masataka Goto
Kiite World: Socializing Map-Based Music Exploration Through Playlist Sharing and Synchronized Listening
Proceedings of the 31st International Conference on MultiMedia Modeling (MMM 2025), pp.197-211, Jan. 2025.
[Paper][Springer] - 佃洸摂,高橋卓見,石田啓介,濱崎雅弘,後藤真孝
Kiite World: マップ上でのプレイリストの共有と楽曲の同期再生に基づくソーシャルな音楽発掘サービス
第29回一般社団法人情報処理学会シンポジウム インタラクション2025, 2025年3月
インタラクティブ発表賞(一般投票)
[Paper] [Slides]
発表資料
第29回一般社団法人情報処理学会シンポジウム インタラクション2025の登壇発表資料です。